

The DataOps Automation Playbook for Modern Teams
To provide enterprise leaders with a strategic and operational guide for implementing DataOps at scale—improving agility, data quality, and decision-making.
Executive Summary
In an age where data is central to decision-making and innovation, organizations are rapidly adopting DataOps to enhance the speed and quality of data delivery. This white paper, "The DataOps Automation Playbook for Modern Teams," presents a comprehensive framework for enterprises looking to leverage DataOps for scalable data excellence.
The paper begins by outlining the current market landscape, offering insights into market sizes, growth projections, and strategic imperatives that highlight the need for DataOps adoption. It explores the process of assessing existing data infrastructure, providing integration strategies, and selecting cloud-native architectures that can support modern data workflows. Furthermore, the paper discusses strategies for optimizing data quality, analytics, and model deployment. It also addresses the growing skills gap and outlines actionable strategies for upskilling existing talent and recruiting new professionals to build high-performance DataOps teams.
Data governance and ethical automation are emphasized, particularly in light of compliance requirements like GDPR and CCPA. The paper concludes by offering a practical roadmap, guiding organizations from short-term pilots to long-term enterprise-wide adoption of DataOps. By following the insights presented in this playbook, organizations can position themselves at the forefront of the DataOps movement, unlocking the full potential of their data assets while ensuring compliance and ethical standards.
1. Introduction
DataOps is a collaborative methodology that integrates people, processes, and technology to streamline the delivery of trusted data across the enterprise. Drawing inspiration from Agile, DevOps, and Lean Manufacturing, DataOps emphasizes continuous integration, automation, and monitoring of data pipelines. The objective is to deliver data faster, more reliably, and at scale while fostering cross-functional collaboration among data engineers, analysts, scientists, and IT operations.
As the volume, velocity, and variety of data grow exponentially, organizations are increasingly unable to rely on fragmented and manual data operations. This leads to delayed insights, poor data quality, and operational bottlenecks, which in turn slow down innovation and increase the risk of making poor business decisions. DataOps addresses these issues by enabling faster data delivery through automated orchestration of pipelines, improving data quality by integrating testing and monitoring throughout the lifecycle, and fostering cross-functional collaboration between data, engineering, and business teams. It also ensures scalable governance to support both agility and compliance. In sectors like finance, healthcare, retail, and manufacturing, enterprises are adopting DataOps to turn data into a continuous, value-generating asset.
This playbook serves as a guide for enterprise decision-makers—CTOs, CIOs, CDOs, and data leaders—looking to implement or scale DataOps. It offers:
- An understanding of DataOps adoption trends and opportunities.
- A framework to assess and modernize existing data infrastructure.
- Best practices for optimizing data quality, analytics, and model deployment.
- Insights into talent strategy, governance, and ethical automation.
- A practical implementation roadmap for short-term pilots and long-term scale.
The ultimate goal is to empower modern teams to operationalize data faster, smarter, and more securely, transforming data operations into a competitive advantage.
“ “The global DataOps platform market is expected to grow from USD 3.9 billion in 2023 to USD 10.9 billion by 2028, at a CAGR of over 23%.” ”
Source: MarketsandMarkets
2. Understanding Quantum Computing
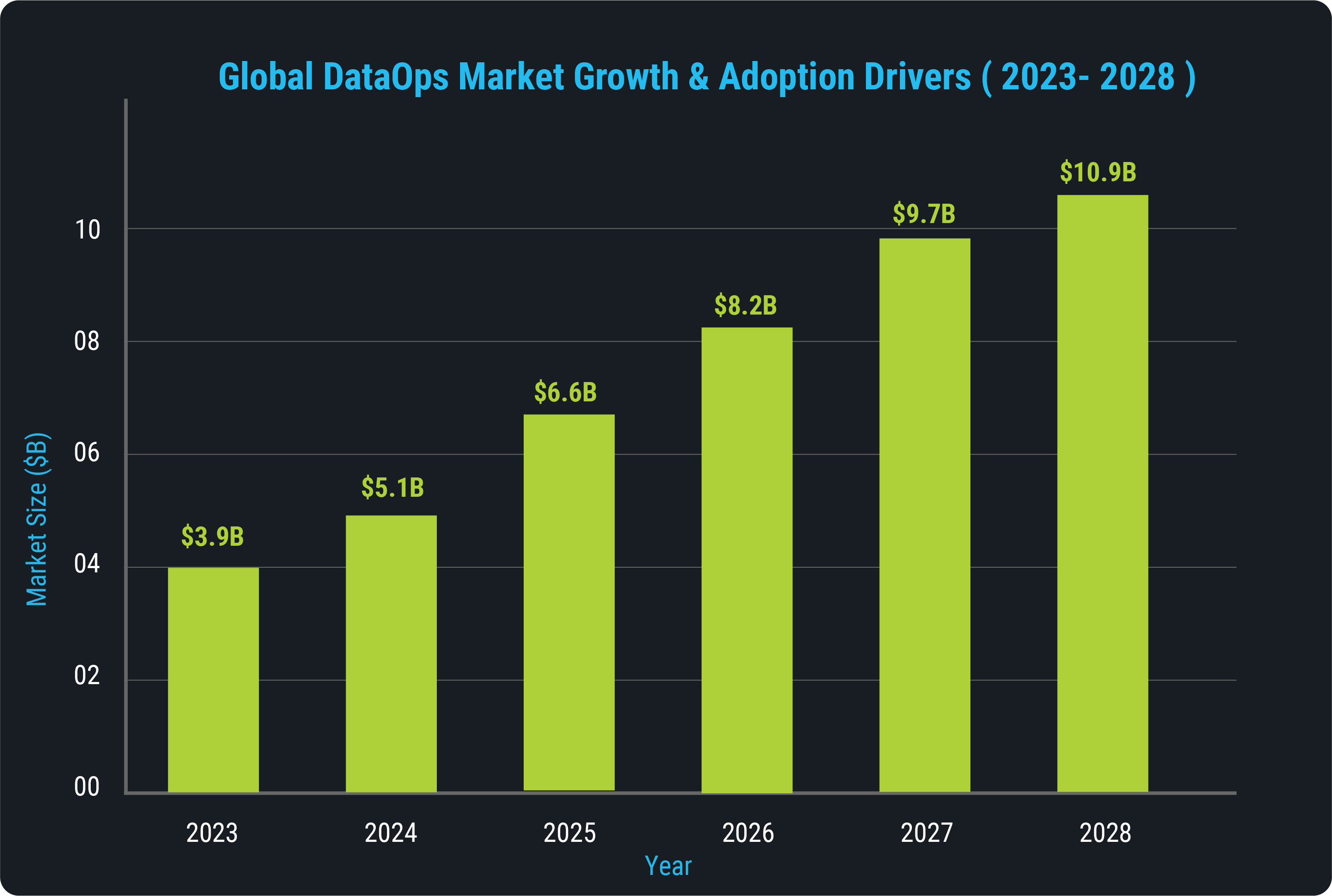
The DataOps market has experienced rapid acceleration over the last five years. This growth is driven by the global demand for real-time analytics, scalable data infrastructure, and AI readiness. According to MarketsandMarkets, the global DataOps platform market is expected to grow from USD 3.9 billion in 2023 to USD 10.9 billion by 2028, at a CAGR of 23%. This rapid expansion is fueled by factors such as the exponential growth in enterprise data, the need for automation to overcome data bottlenecks, and the growing pressure to operationalize AI/ML models quickly. Key drivers of this growth include the rise in multi-cloud environments and the increasing complexity of data across organizations. As more enterprises seek to modernize their data infrastructure, DataOps is transitioning from a niche capability to a mainstream strategy.
Adopting DataOps provides companies with a clear competitive advantage by reducing cycle times for analytics delivery, increasing data quality, and promoting cross-functional collaboration. Companies that implement DataOps see measurable improvements in time-to-insight, decision-making, and data governance.
Leading companies are already reaping the rewards of DataOps. For example, Pfizer leveraged DataOps to accelerate data availability, reducing processing delays and enabling faster experimentation. ING streamlined its data compliance processes, supporting quick regulatory updates. Similarly, Shell deployed DataOps to enhance operational analytics, boosting predictive maintenance and asset efficiency.
For decision-makers, the imperative is clear: investing in DataOps today is an essential step toward building data agility, resilience, and long-term innovation capacity.
3. Framework for DataOps Infrastructure Assessment
Before deploying DataOps, organizations need to assess their existing data architecture to identify inefficiencies and gaps. This comprehensive infrastructure audit should cover several areas:
- Data pipeline architecture and automation readiness.
- Metadata and lineage tracking tools.
- Scalability and latency of data storage systems.
- Integration with AI/ML platforms and existing DevOps tools.
This baseline assessment ensures that DataOps initiatives align with real operational needs and existing investments.
Integration is the cornerstone of DataOps success. Organizations should focus on:
- Modular architecture for interoperability.
- Real-time data synchronization across tools like ETL, ELT, and workflow orchestrators.
- RESTful APIs and event-driven architecture for responsive systems.
Tools like Apache Kafka, Fivetran, and Snowflake help stitch together modern DataOps ecosystems, providing seamless integration.
Cloud-native platforms are crucial for DataOps deployments, providing elasticity, scalability, and cost efficiency. Benefits include:
- On-demand resource provisioning.
- Centralized governance and data cataloging.
- Seamless scaling for both batch and streaming data workloads.
Leading cloud providers such as AWS, Azure, and Google Cloud offer tools that can support these architectures. Choosing the right cloud provider depends on factors like latency, compliance, and AI integration readiness.
“ “By 2026, data engineering teams using DataOps practices and tools are expected to be ten times more productive than those that do not.” ”
Gartner Strategic Planning Assumption
4. Optimizing Data & Model Strategy
Data quality is a foundational pillar for reliable analytics and model performance. Poor data quality introduces risks, leading to inaccurate insights and increased operational costs. Enterprises can ensure high-quality data by using:
- Automated data validation tools to detect anomalies in real-time.
- Data profiling and cleansing pipelines to remove duplicates and inconsistencies.
- Data lineage tracking to ensure transparency in data transformations.
Continuous monitoring of data health is essential, and frameworks like Monte Carlo and Acceldata can provide real-time data observability.
Integrating predictive models into data pipelines is key to real-time decision-making. Key strategies include embedding machine learning models as microservices and using orchestration tools like Prefect and Airflow to coordinate model training, scoring, and re-training tasks.
Organizations should also implement model version control through tools such as MLflow and DVC to manage iterations and rollback. Furthermore, utilizing feature stores like Tecton and Feast ensures consistency between training and inference environments.
A robust predictive analytics pipeline is essential for driving timely, actionable insights across the organization. Key components include:
- Data ingestion layers that support batch, real-time, and event-driven data flows.
- ETL/ELT processes optimized for model readiness.
- Feature engineering tools for data preparation.
Real-time processing frameworks like Apache Flink and Spark Streaming enable critical use cases such as fraud detection and demand forecasting.
5. Addressing the Skills Gap & Talent Ecosystem
DataOps demands a blend of skills from data engineering, DevOps, and AI/ML operations. However, there is a significant talent gap. Key areas of deficiency include expertise with orchestration tools like Apache Airflow and Dagster, CI/CD pipelines for data workflows, and knowledge of cloud-native data services and container orchestration tools like Kubernetes.
Organizations are facing challenges in filling DataOps roles, which often leads to inefficiencies when responsibilities are redistributed across siloed teams.
Enterprises can close the skills gap by prioritizing internal upskilling and strategic hiring. This can include:
- Internal Training: Developing custom learning paths focused on tools, pipelines, and data governance.
- Vendor Certifications: Encouraging certifications from AWS, GCP, Databricks, and dbt Labs.
- Hackathons & Workshops: Simulating real-world DataOps challenges to build practical expertise.
Recruiting professionals with DevOps experience and training them in data-specific contexts is also an effective approach.

Culture plays a crucial role in how DataOps teams collaborate. A high-performance DataOps culture is characterized by:
- Cross-functional collaboration between data engineers, scientists, and business teams.
- Continuous feedback loops for pipeline and model refinement.
- Shared ownership of data reliability and delivery outcomes.
Leaders must invest in building a workplace that encourages collaboration, accountability, and continuous learning.
6. Establishing Governance & Ethics Principles
Effective data governance is critical for securing and scaling DataOps practices. It ensures that data remains consistent, accurate, and accessible. Key principles of governance include:
- Clear data ownership and stewardship.
- Standardized data definitions across departments.
- Streamlined regulatory compliance.
Integrating governance within DataOps ensures that data remains controlled as volumes and complexity increase. Organizations must comply with regulations such as GDPR, CCPA, and HIPAA. Compliance mechanisms should include:
- Real-time monitoring of data access.
- Role-based access control (RBAC).
- Encryption at rest and in transit.
- Automated audit trails for data transformations.
These controls help organizations manage compliance while safeguarding sensitive data.
Ethics in DataOps is a strategic concern. The automation of data handling and model deployment raises risks related to bias, transparency, and unintended consequences. Ethical DataOps includes:
- Fairness and bias detection protocols for decision systems.
- Implementing tools for explainability in data transformations and models.
- Regular governance reviews to audit algorithmic impacts.
Embedding ethical practices into DataOps ensures compliance, public trust, and responsible data use.
7. Delivering a Practical Roadmap

For organizations new to DataOps, small, focused pilot projects offer a low-risk way to demonstrate value. Pilots should focus on high-impact workflows, such as automating data ingestion, with clear KPIs for measuring success.
“ "Quantum computers will eventually solve problems classical computers practically never could." ”
Google AI Quantum Team
Once pilots have proven successful, the organization can begin scaling DataOps. The adoption process involves:
- Consolidating learnings from pilots and refining tooling.
- Standardizing DataOps practices across teams.
- Building governance at scale and promoting cultural alignment.
Continuous optimization and leadership support are critical for enterprise-wide DataOps adoption.
8. Conclusion
DataOps has become a crucial enabler of modern data excellence, allowing enterprises to accelerate insights, maintain agility, and ensure quality. This playbook provides a roadmap for implementing DataOps from market understanding and infrastructure assessment to optimizing pipelines and building a collaborative culture. By starting with pilots and scaling to enterprise-wide adoption, organizations can unlock substantial value and position themselves as leaders in data-driven innovation.
“ “Enterprises relying on data management tools for decision-making are 58% more likely to beat revenue goals and 162% more likely to exceed them significantly.” ”
Google AI Quantum Team

Services
Industries
Company Insights
At theHeart of Deep Tech
Made with![]() in San Francisco, USA
in San Francisco, USA




All rights reserved © 2025Cloudangles.